إطلاق جوجل لنموذج EmbeddingGemma: دقة عالية وكفاءة مذهلة في معالجة اللغة الطبيعية على الأجهزة المحمولة
يُعلن عملاق التكنولوجيا جوجل عن إطلاق نموذج EmbeddingGemma، وهو نموذج مضمّن نصي مفتوح المصدر مُحسّن للذكاء الاصطناعي على الأجهزة، يجمع بين الكفاءة العالية وأداء استرجاع متطور. يُعدّ هذا النموذج نقلة نوعية في مجال معالجة اللغة الطبيعية، حيث يوفر أداءً استثنائياً مع حجم صغير يسمح بتشغيله على الهواتف المحمولة وحتى في بيئات العمل دون اتصال بالإنترنت.
حجم صغير وأداء قوي
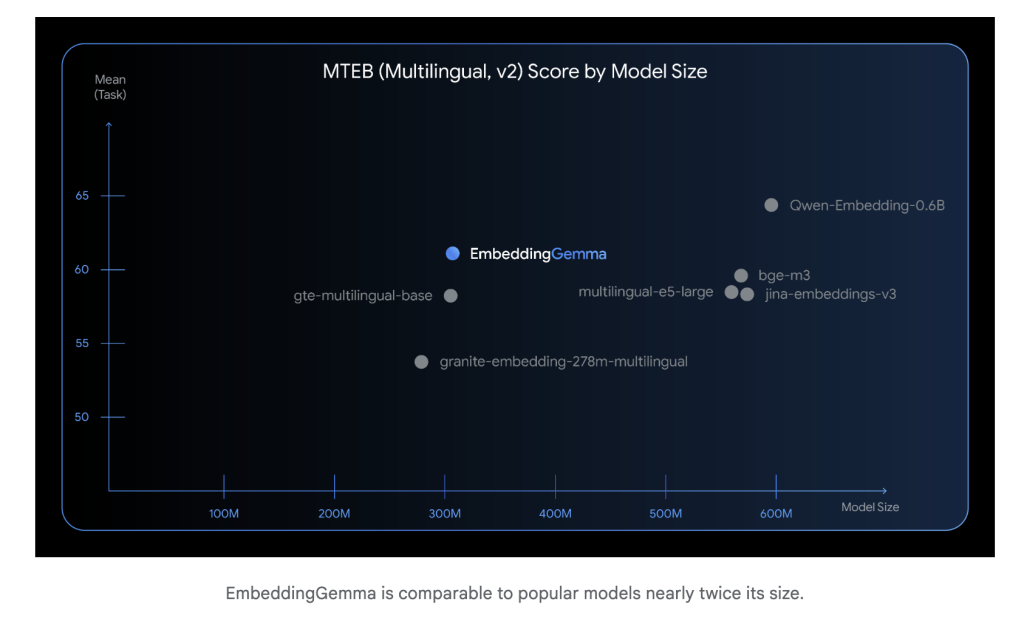
يحتوي EmbeddingGemma على 308 مليون معلمة فقط، مما يجعله خفيفاً بما يكفي للعمل على الأجهزة المحمولة وبيئات العمل المنفصلة. وعلى الرغم من حجمه الصغير، إلا أنه يتنافس مع نماذج مضمّنة أكبر بكثير من حيث الأداء. كما يتميز بانخفاض زمن الاستدلال (أقل من 15 مللي ثانية لـ 256 رمزاً على EdgeTPU)، مما يجعله مناسبًا للتطبيقات التي تتطلب الاستجابة في الوقت الفعلي.
دقة متعددة اللغات
تم تدريب EmbeddingGemma على أكثر من 100 لغة، وحقق أعلى تصنيف في مقياس Massive Text Embedding Benchmark (MTEB) بين النماذج التي تقل عن 500 مليون معلمة. يتفوق أداءه على نماذج مضمّنة أكبر منه بحجم يقارب الضعف، خاصة في استرجاع النصوص متعددة اللغات والبحث الدلالي.
البنية الأساسية
يعتمد EmbeddingGemma على بنية مشفرة قائمة على Gemma 3 مع دمج المتوسطات (mean pooling). من المهم ملاحظة أن البنية لا تستخدم طبقات الاهتمام الثنائية الاتجاه الخاصة بالوسائط المتعددة التي تستخدمها Gemma 3 لإدخال الصور. بدلاً من ذلك، يستخدم EmbeddingGemma مجموعة من مُشفّر المُحوّل القياسي مع الانتباه الذاتي الكامل للتسلسل، وهو أمر نموذجي لنماذج تضمين النصوص. يُنتج هذا المُشفّر تضمينات ذات أبعاد 768، ويدعم تسلسلات تصل إلى 2048 رمزًا، مما يجعله مناسبًا جدًا لجيل التعزيز باسترجاع المعلومات (RAG) وبحث الوثائق الطويلة. وتضمن خطوة دمج المتوسطات تمثيل متجهات بطول ثابت بغض النظر عن حجم الإدخال.
مرونة التضمينات
يستخدم EmbeddingGemma تقنية تعلم التمثيل المتداخلة (MRL). يسمح هذا بتقليل أبعاد التضمينات من 768 إلى 512 أو 256 أو حتى 128 بحد أدنى من فقدان الجودة. يمكن للمطورين ضبط التوازن بين كفاءة التخزين ودقة الاسترجاع دون الحاجة لإعادة التدريب.
التشغيل دون اتصال بالإنترنت
صُمّم EmbeddingGemma خصيصًا للاستخدام على الأجهزة دون اتصال بالإنترنت. بما أنه يتشارك مُجزّئ النصوص (tokenizer) مع Gemma 3n، يمكن لنفس التضمينات تشغيل خطوط أنابيب الاسترجاع المدمجة مباشرةً لأنظمة RAG المحلية، مع فوائد خصوصية توفيرها من خلال تجنب الاستدلال السحابي.
الأدوات والأطر التي تدعم EmbeddingGemma
يتكامل EmbeddingGemma بسلاسة مع:
- Hugging Face: (transformers، Sentence-Transformers، transformers.js)
- LangChain و LlamaIndex: لخطوط أنابيب RAG
- Weaviate وقواعد بيانات المتجهات الأخرى
- ONNX Runtime: للنشر المُحسّن عبر المنصات
يضمن هذا النظام البيئي قدرة المطورين على دمجه مباشرةً في سير العمل الحالي.
كيفية التنفيذ العملي
-
التحميل والتضمين:
from sentence_transformers import SentenceTransformer model = SentenceTransformer("google/embeddinggemma-300m") emb = model.encode(["مثال على نص للتضمين"]) -
ضبط حجم التضمين: استخدم الأبعاد الكاملة 768 للحصول على أقصى دقة، أو قللها إلى 512/256/128 للحصول على ذاكرة أقل أو استرجاع أسرع.
-
التكامل مع RAG: قم بتشغيل بحث التشابه محليًا (تشابه جيب التمام) وأرسل أفضل النتائج إلى Gemma 3n للجيل. يُمكّن هذا خط أنابيب RAG دون اتصال بالإنترنت بالكامل.
لماذا EmbeddingGemma؟
- كفاءة على نطاق واسع: دقة عالية في استرجاع النصوص متعددة اللغات مع حجم صغير.
- المرونة: أبعاد تضمين قابلة للتعديل عبر MRL.
- الخصوصية: خطوط أنابيب دون اتصال بالإنترنت من الطرف إلى الطرف بدون تبعيات خارجية.
- سهولة الوصول: أوزان مفتوحة، ترخيص مرن، ودعم قوي للنظام البيئي.
يُثبت EmbeddingGemma أن نماذج التضمين الأصغر يمكن أن تحقق أفضل أداء في الاسترجاع مع كونها خفيفة الوزن بما يكفي للنشر دون اتصال بالإنترنت. وهو يمثل خطوة مهمة نحو ذكاء اصطناعي فعال، يحترم الخصوصية، وقابل للتطوير على الأجهزة.
للمزيد من المعلومات والتفاصيل التقنية، يُرجى زيارة رابط الصفحة التقنية و[صفحة GitHub](رابط صفحة GitHub).
مواضيع مشابهة:
 DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
 بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena
بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena

اترك تعليقاً